In the last post I analyzed 80 news articles from Taiwan over the period of 6 weeks, provided some basic statistics and tried to come up with a Chinese characters frequency list, by counting the occurrence of unique characters in these articles. In this post I would like to write about the word frequency analysis of these articles.
Research method
I again analyzed the same 80 articles which were divided into 4 areas: 國際 (international), 政治 (domestic politics), 社會 (society) and 財經 (economics) with 20 articles in each area.
During the whole word frequency analysis process, the biggest problem was to actually separate Mandarin words from each other. Like I mentioned in the previous post, as most of those studying or speaking Chinese know, words are not separated by spaces in Chinese. Counting the occurrence of unique words as opposed to counting the occurrence of unique characters therefore requires much more work, because unless you want to count word frequency with a pen and paper and would like to use a computer program to do the work for you, there has to be something that separates words from one another, in order for the program to know what to count. There are fairly complicated computer programs that can do this sort of indexation for Mandarin automatically, but since I didn't have any of those, I had to do indexation manually.
In order to count the occurrence of unique words in an English article for instance, the process would be much easier, because spaces between words in English texts mark very clearly where a word starts and where a word ends and a computer program can thus use these spaces as index markers to count words and consider everything in between those spaces to be separate word units. In Mandarin this is unfortunately not possible.
Take the following sentence for example:
伊拉克西部兩個警察辦公室遭到攻擊.
Two police stations in a western part of Iraq were attacked.
There is a total of 8 words in the Mandarin sentence, but as you can see none of the words are separated by spaces so simple indexation based on spaces between words is not possible and as I said since I didn't have any program to index Mandarin words for me, I had to do it manually. What I did was, that I basically put my 80 articles into a text editor, read them and put each word onto a new line in the document. Since I had to press Enter every time I did that, each word was indexed with the 'enter' symbol. It was very time consuming, but I didn't come up with anything more intelligent.
After I did that, I used the same program my friend wrote to count the number of unique characters, to count the number of unique words, which were now indexed by the return symbol. I put the data the program produced into Open Office Calc and started to do some statistical work.
The most questionable part of the whole process was actually the word indexation itself because I subjectively decided what should and what should not be indexed as a unique word. Often I was wondering for instance, whether or not to further separate words, whether to index 遭到 as a unique word or index 遭 and 到 separately. I kept changing my own 'word separation rules' as I was going through the articles and even though I always tried to reedit the entire data file with every change I made, there most probably are some things that I overlooked.
Here are some of the rules that I applied for word separation:
- I counted every numeral as a separate word, regardless of whether it was a cardinal number, ordinal number or a part of a larger number. (i.e.:第三百六十二 = 第+三+百+六+十+二)
- I counted every numerator separately (i.e.: 一個 = 一 + 個; 一些 = 一 + 些)
- I counted the ordinal prefix 第 separately (i.e.:第一 = 第 + 一)
- I counted 的 separately (他的 = 他+的)
- I counted every word in a name or compound that could be used as a separate word separately. (i.e.: 中央廣播電台 = 中央 + 廣播 + 電台. 中央廣播電台 means Central broadcasting station, which is the official name of the station, could be used as one word, but since 中央 - central, 廣播 - to broadcast and 電台 - station can be used separately, I decided to count them separately)
- I did't count the word city (市) or county (縣) in a name of a city or county separately (i.e.:台北市 = 台北市;台北縣 = 台北縣)
- I separated expressions such as 在開會前 in the following way: 在前 + 開會
- Where 上, 下 acted as verbs, I counted them as separate words
- Where 上,下 were parts of constructions such as: 在路上 I separated them in the following way: 在上 + 路
- I counted 上 or 一 used in fixed expressions such as 馬上 or 一樣 as one word
- I counted personal names, names of places, names of foreign organisations ect. as separate words (i.e.: 馬英九 = 馬英九) unless rule 5 could be applied.
- I counted ad hoc abbreviations as separate words (if 美牛 (originally a non-existant word) was used to represent 美國牛肉, I counted 美牛 as a separate word, and did not further separate it as 美 + 牛)
Data analysis

This is the basic word count table, showing the total number of words and unique number of words occurring in the four analyzed sections, as well as their total count.
As you can see, I found a total of 5901 unique words in these 80 articles. The first conclusion is that there were more unique words in these 80 articles (5901) than there were unique characters (2105 - please see last post for more information). This is simply due to the fact that the same character can be a part of several different words and there are therefore more unique character combinations (words) than there are unique characters.
Another fairly intuitive conclusion is that there was a lower total amount words (21089) compared to a higher total amount of characters (38085) in the articles. This is because of the fact that as mentioned before, a lot of words are built up of 2 or more characters and there were therefore less words than characters in these 80 articles in total.
A third conclusion is a supporting argument to the fact that the number of characters you know is less important than the number of words you know. As I mentioned in my previous post, characters represent first and foremost morphemes and not words. It is true that there are many single character words, but most Mandarin words are made up of two or more characters. Based on my character frequency count I found, that there were only 2105 unique characters in the 80 articles I analyzed. One could say that learning 2105 characters is not such a terribly hard thing to do, but actually characters as I said don't matter that much and as you see, I found a total of 5901 unique words in the articles I analysed which is almost 3 times as much as the total amount of unique characters I found.
It is true, that once you know a lot of characters and what meaning they usually have in multiple character words it is easier to guess the meaning of a multiple character word that you've never seen before, if this word consists of characters that you already know. If for instance you know the character for ice 冰 and the character for box 箱 and you see the word 冰箱, which means refrigerator, you will probably guess correctly its meaning. You might wonder if it's a freezer or just a refrigerator, or some sort of a cooling box for food, but looking at the context in which this word appeared, it should be fairly easy to guess what it means. This however is not necessarily always the case. If you know the characters for electricity - 電 and to look - 視 and see the word 電視, even after looking at the context it appeared in you might have a hard time guessing that it means television.
These are all only very simple examples. Mandarin words and sentences are sometimes ridiculously complicated, or are of foreign origin and simply cannot be guessed. On top of that, while reading news, if you are a translator for instance, a rough guess is often not enough. Needless to say, that as with any language that you learn, knowing every word and every character in a given sentence does not necessarily mean that you will understand the sentence as a whole.
After plotting the data onto the x and y axes, the Word knowledge Vs. Text recognition looked something like this:
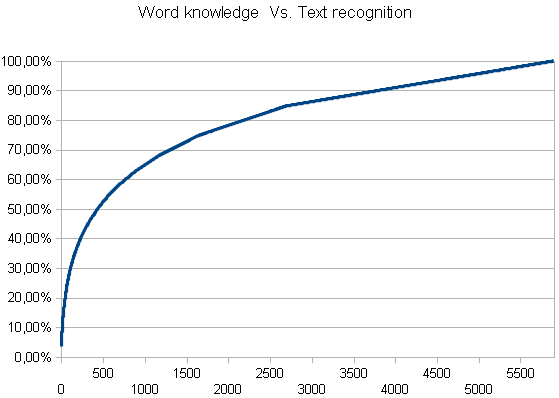
This chart is similar to the character frequency chart, but as you can see, there is quite a difference on the x axis at around the 50% point, where the chart sort of takes off in a linear fashion. The reason for this is that this is the point on the chart where very rare words start to occur (words that occurred only once in the sampled 80 articles) and the chart thus turns into a linear ascending line.
Again, as with the character analysis, if you look at this chart, you can see, that by knowing the first 50% of the most frequent words in the data I sampled, you should be able to recognize around 85% of the text I sampled but as I mentioned in my earlier post, even though 85% is a relatively high amount, should you come across a word from the remaining 15% of the chart (which you will), it is highly probable that you will not recognize it. 15% might not sound like a lot, but if you even it out, it actually accounts for almost every 6th word and this every 6th word might be evenly distributed across the whole article you read or could be jammed into the most important sentence in the article.
For reference, as with the character analysis, I also made rare a word occurrence table, just to give you a sense of how much of the total amount of unique words do the rare words (words that occurred only once, twice ore three times) account for:

As you can see, this number is huge. 80% of all unique words that occurred in the articles I sampled, occurred only once, twice or three times and on the other hand there were only 35 words in total, that occurred more than 50 times. Rare words thus accounted for more than 80% of the text I sampled. This sadly means, that you simply have to learn a very large amount of words to be able to recognize a large amount of a text. Another way to look at it is that in order to cover the remaining 30% of text (roughly the amount for which the rare words account for) you will have to learn the remaining 80% of unique words which is 4729 words in our case and by learning each new word you will cover only slightly more of the texts, since each new word you learn appeared only once, twice or three times in the texts I sampled.
Maybe another way to look at it would be, that should you substitute every rare word with a blank space, 30% of the articles I analyzed would be made up of blank spaces and in order to fill them up, you would need to learn 4 times as many words as you already know.
Again for reference I am posting the list of the 80 most frequent words that occurred in the articles I sampled

表示 - to say, to express
中央社 - Central news agency
報導 - to report, report
經濟 - economy
總統 - president
台北 - Taipei
下午 - afternoon
台灣 - Taiwan
大陸 - Mainland China
美國 - USA
上午 - Morning
指出 - to point out, to say
警方 - police, police officials
中國 - China
記者 - reporter
政府 - government
今天 - today
今年 - this year
國民黨 - Kuomintang political party
馬總統 - president Ma YingJiu
歐巴馬 - Barack Obama
國家 - country
投資 - to invest
You can download the full word frequency list in the download section of this blog.
End of Part II. Since I based my study only on 80 articles, in Part III, I will try to make some estimations about how many characters and words one should know to be able to read news in general.
Okay,I know this comment is not related to this post, but i am super excited to find a polyglot that is a Slovak. Having a Slovak heritage made me want to learn the language, which sprung my interest into all languages. And i was hoping you could give me some advice on learning Slovak and maybe have some book references or something to help me along because Im kind of lost and getting discouraged. Thank you very much.
ReplyDeleteDear Michael,
ReplyDeletethank you for the nice words.
Unfortunately I don't know what kind of advice to give you when it comes to Slovak :( It is the typical situation where other foreigners learning the foreign language you want to learn are much more useful than native speakers. What I would teach you or the advice I would give you would only cover what I find complicated in Slovak and things that might be completely alien to you, but absolutely natural to me, I wouldn't even mention.
There is a language forum, maybe you have heard of it: www.how-to-learn-any-language.com (including the hyphens) which despite the over-marketed name is quite a good place for language lovers and learners and there are many articles about Slovak. There is a forum member called Chung who is an absolute expert on Slovak (and all of the other Slavic languages as well), you might find his posts very interesting.
Two of his nice posts:
http://how-to-learn-any-language.com/e/languages/slovak/index.html
http://how-to-learn-any-language.com/forum/forum_posts.asp?TID=26165&PN=1
I don't know how advanced you're Slovak is right now, but if your passive understanding is good, you can go straight ahead and listen to Slovak news everyday. That is great practice. I have the link in the language learning resources section.
hope it helps
best regards
Vladimir
Good Series.
ReplyDeleteMy Chinese Newspaper teacher once told me you only need to know 2000 words to read ANY news article. But, he added, the 2000 words you need to know will be different for each article you read.
Dear Steven,
ReplyDeletethank you for your comment.
I guess this could be said about any two diferent news articles in any langauge using a different number:)
Vladimir
Hello Vladimir, I am just curious if 2 years later there is now any program than segments chinese texts into individual words?
ReplyDeleteHello Eji,
ReplyDeleteI haven't done any work with character or word frequency sampling for quite some time, so I am not sure, but I think that even at the time when I was writing these articles, there were programs that would compare sampled texts to extensive word databases and produce frequency lists that way. I haven't done any research, so I unfortunately don't know where to find them.
I don't think it is too difficult to write programs like that, the problem is the extensive word database, so I'm thinking that maybe Chinese departments of big Chinese universities might have something like that, but it's only a guess.
Vladimir
Would this online Chinese-to-pinyin converter provide a solution?. The pinyin is segmented into words showing which characters make up each word.
ReplyDeletewww.purpleculture.net/chinese-pinyin-converter/
Hello and thank you for the link.
ReplyDeleteI tried the converter and it's not that bad. From what I understand, it also segments characters into words which is great, but needs a bit of polishing. You would still need to go through the entire text and manually edit it yourself. It makes mistakes like: 認 + 為 instead of 認為; 因 + 為 instead of 因為;細 + 數 instead of 細數;臉 + 書 instead of 臉書 etc.
Still I would say it got about 70-80% right, but I would need to try and work on a few texts to see how much time it would really save. Maybe in conjunction with another program.. who knows.
Thank you for the link again.
All the best,
Vladimir